---
title: "PART 1 Non-parametric Test 第一部分 非参数检验"
---
```{r setup, include=FALSE}
source(here::here("_common.R"))
knitr::opts_chunk$set(echo = TRUE, message = FALSE, warning = FALSE)
```
# 非参数检验
::: rmdnote
**为什么非参数检验**
当数据不满足正态分布、方差齐性等参数检验前提(往往实际生活中数据更多就是这样),或样本量较小、变量为顺序尺度时,非参数检验更稳健。它不依赖总体分布假设,对异常值不敏感,适用范围更广,能在分布未知或偏离严重的情况下提供可靠的统计推断结果
:::
## 第一章.Compare distributions比较样本的分布
### ①*Non-parametric Test I独立样本非参数检验*
#### 1.1Chi-square test卡方检验
##### 1.1.1 Chi-square Goodness-of-fit 卡方拟合优度检验
用于将 \*\* 观测频数(观测分布)与期望频数(期望分布)\*\* 进行比较。\
*H0:观测频数与期望频数无显著差异。\
*用于判断:由原假设设定的总体分布(任意分布!),与实际得到的样本分布的拟合优度(契合程度)。\
无需对总体分布做任何假设,因此属于非参数检验,也叫无模型检验。
```{r Goodness_of_fit_test}
# Goodness-of-fit test
# example:major reason to choose a course举个例子:选课的主要原因,我们假设选课概率是相等的,服从均匀分布
#rm(list = ls()) 删除现有工作台,防止加载不出什么东西
# actual frequencies实际上的频数
f_o = c(18, 17, 7, 8)
# expected frequencies(normalized)理论上的分布(正态)
prob = rep(1/length(f_o), length(f_o)) # uniform均匀分布
# Conduct the test实施检测
chisq.test(f_o, p = prob)#简单的计算
chisq.test(f_o, correct = T, p = prob)
chisq.test(f_o, y = NULL, correct = F, p = prob, rescale.p = F)
# Let's try some new expected frequencies尝试些别的理论分布
prob = c(4,3,2,1)
# Conduct the test
# turn the rescale option to 'T' to normalize p
chisq.test(f_o, p = prob, rescale.p = T)
#核心函数就是chisq.test(被测数据,correct=是否连续矫正,p=理论分布)
#同时点击ctrl+alt+r运行,运行结果如下
```
##### 1.1.2.卡方独立性检验(Chi-square test for independence),
专门用来判断两个分类变量之间是否存在关联(是否相互独立)。\
数据必须以列联表(矩阵)形式呈现,每个单元格是分类频数,不能是连续的等距或者等比数据。\
*H₀:两个变量相互独立(无关联);*\
*H₁:两个变量不独立(存在关联)*
```{r Chi-square-test-for-independence}
# 卡方独立性检验适用于两个分类变量
# 假设情景:研究学生是否参加课外辅导与期末成绩是否及格之间的关联
# 第一个变量:辅导参与情况(“参与” vs “未参与”)
# 第二个变量:成绩是否及格(“及格” vs “不及格”)
# 预期参加辅导的学生及格比例更高,但存在个体差异和其他影响因素
# 读取生成的数据
study_data <- read_xlsx(here("data", "excel-files", "Chi-square-test.xlsx"))
# 提取两个分类变量
x <- study_data$tutoring # 辅导参与情况
y <- study_data$grade # 成绩等级
# 创建列联表
contingency_table <- table(x, y)
# 进行卡方独立性检验
# 因为这是 2×2 列联表,设置 correct = FALSE 不进行连续性矫正
test_result <- chisq.test(contingency_table, correct = FALSE)
# 提取卡方统计量
chi_square <- test_result$statistic
# 计算总样本量
n_total <- sum(contingency_table)
# 确定行数和列数的最小值(对于 2×2 表,k = 2)
k <- min(dim(contingency_table))
# 计算 Cramer's φ
cramer_phi <- sqrt(chi_square / (n_total * (k - 1)))
# 输出结果
test_result
cat("Cramer's φ: ", cramer_phi, "\n")
```
#### 1.2 Binomial test 二项检验:检验数据是否符合二项分布
二项分布(Binomial Distribution)描述的是 n 次独立重复伯努利试验中,\
成功次数 X 的概率分布,每次试验只有 “成功或者失败” 两种互斥结果,且成功概率 p 固定不变。\
它只由两个参数决定:试验总次数 n(总 trials 数)和单次成功概率 p(0 \< p \< 1),记为 X∼B(n,p)。\
专门用于只有两种结果的分类数据,比如抛硬币正反面、博彩任务选 A\\B、问卷选是 \\ 否,\
完全不依赖正态分布等参数假设,是典型的非参数精确检f验。\
*原假设*$H_0$*:真实成功概率 p=p0*\
```{r Binomial_test }
# example: to test whether the subject is guessing during a gamble task
#举例子:去检验一个几十次的博彩任务是否随机
binom.test(x = 1222, # the trials choosing option 0/1选1的情况
n = 2666, # the total trials总次数
p = .5, # H0:the probability of success is equal to 0.5
alternative='two.sided')
#>binom.test(x=其中一种情况发生的次数,n=总数,p=理论上的概率)
#1222 次成功,2666次总试次
```
#### 1.3 Runs test 游程检验
*看二项过程是不是随机产生*
游程检验是用于检验二分类序列是否为随机序列的非参数检验,核心通过统计连续相同符号的“游程”数量,判断序列是否存在非随机规律。\
它不依赖数据的分布形态,仅基于序列的顺序和符号分类,是检验时间序列、二项过程随机性的经典方法。\
游程数量过多或过少,都意味着序列存在非随机模式:游程过少代表序列存在聚类趋势,游程过多代表序列存在交替趋势。\
通过比较实际游程数与理论期望游程数的差异计算p值。\
该检验适用于二分类数据的随机性检验,如博彩任务选择、抛硬币序列、时间序列的趋势检验等场景。\
(注意算一个值的游程和另一个值的游程相加是总游程)
H0:序列是随机产生的
```{r Runs-test}
#其实什么包的不用太管,考试的话全给你安装了,
#平时想不起来先运行了等它报错就自己告诉你了。
#可能为数不多比较坑的地方就是很少有时候是由重名的函数的,特别是环境里函数一多就容易混
#这个时候就要对应的包::你要的函数()这样强制调用
# 游程检验适用于判断二元序列是否随机
# 假设情景:某工厂质检员记录产品是否合格,想检验不合格品的出现顺序是否是随机的
# 变量含义:产品检验结果,1 表示合格,0 表示不合格
# 预期如果生产稳定,合格与不合格的出现应是随机的,但可能存在批次效应或周期性
# Load the package used to conduct the test
# 加载DescTools包,该包提供了RunsTest()函数用于游程检验
#library(DescTools)
# 对runs_data的第1列数据执行游程检验(注意函数名RunsTest大小写敏感)
# 生成模拟数据:某工厂连续60天的产品合格情况(1=合格,0=不合格)
set.seed(123)
runs_data <- data.frame(
quality = sample(c(0, 1), size = 60, replace = TRUE, prob = c(0.2, 0.8))
)
DescTools::RunsTest(runs_data[[1]],
alternative = 'two.sided', # 双侧检验:实际游程数 ≠ 期望游程数,即序列非随机
exact = TRUE) # 计算精确 p 值(适合小样本,这里样本量 60 也可用)
```
#### 1.4 K-S test
K-S 检验是基于经验累积分布函数(ECDF)的非参数检验,分为单样本和两样本两种形式,核心通过比较两个分布的累积分布函数的最大垂直距离(D 统计量),判断分布是否存在显著差异。\
**单样本 K-S 检验**用于检验单个样本是否服从某一理论分布(如正态分布),\
**两样本 K-S 检验**用于检验两个独立样本是否来自同一总体分布。它不依赖总体参数假设,对分布的位置、形状、偏态等差异都敏感,是检验分布拟合优度和两样本分布一致性的经典方法。\
其原假设为两个分布完全相同,备择假设为分布存在差异,通过 D 统计量和 p 值判断是否拒绝原假设,D值越大、p值越小,分布差异越显著。\
该检验适用于连续型数据的分布检验,对ties(相同值)敏感,单样本检验中存在 ties 会影响 p 值准确性,需注意数据预处理。
```{r K-S-test}
# 假设情景:某中学数学老师想检验班级学生的期末考试成绩是否服从正态分布
# 变量含义:score 为学生的数学测验分数(百分制,0-100)
# 预期成绩可能略呈左偏(高分偏多)或右偏(低分偏多),不完全符合正态分布但接近
# 读取指定路径的 xlsx 数据文件
ks_data <- read_xlsx(here("data", "excel-files", "Ks_test_data.xlsx"))
# 查看数据前6行,快速预览数据结构
head(ks_data)
# 查看数据的详细结构(变量类型、长度等)
str(ks_data)
# 基于样本数据的均值和标准差,生成一个同参数的正态分布随机数(用于两样本 K-S 检验)
# length(ks_data$score):样本量,mean(ks_data$score):样本均值,sd(ks_data$score):样本标准差
norm0 <- rnorm(length(ks_data$score), mean = mean(ks_data$score), sd = sd(ks_data$score))
# 进行 K-S 检验
# 1. 两样本 K-S 检验:比较样本数据 ks_data$score 与生成的正态分布数据 norm0 的分布是否一致
# 如果 p 值 > 0.05,说明两者分布无显著差异,即样本分布与正态分布一致
ks.test(ks_data$score, norm0)
# 2. 单样本 K-S 检验:直接检验样本数据 ks_data$score 是否服从指定参数的正态分布
# pnorm 为正态分布的累积分布函数,mean 和 sd 指定理论正态分布的参数(与样本一致)
# 注意:当样本来自连续分布时,此方法比两样本法更直接,但若数据中有较多重复值会给出警告
ks.test(ks_data$score, "pnorm", mean = mean(ks_data$score), sd = sd(ks_data$score))
# 其他理论分布检验
# ks.test(观测值, "pnorm", mean, sd) # 正态分布
# ks.test(观测值, "punif", min, max) # 均匀分布
# ks.test(观测值, "pexp", rate) # 指数分布
# ks.test(观测值, "plnorm", meanlog, sdlog) # 对数正态分布
```
### *②Non-parametric Test II双样本非参数检验*
#### 2.1Two paired sample配对样本检验
##### 2.1.1.Sign test
\
*作用:检测配对数据是否存在显著差异,只在意差异的方向\
H0:配对数据没有显著差异 原理是配对数据互相减,看符号 是0会删掉,然后用二项分布算概率*
```{r SIGNtest}
# Load the package
#library(BSDA)
# Pre-train scores
pre <- c(70, 62, 88, 68, 81, 84, 64, 86, 27, 76)
# Post-train scores
post <- c(80, 86, 77, 73, 91, 81, 72, 89, 72, 79)
# Conduct the test
SIGN.test(pre, post, alternative="two.sided")
#SIGN.test(pre,post,alternative=”two.sided”)
#前两位放配对数据
#p>0.05不拒绝H0
```
##### 2.1.2. Wilcoxon T test
WilcoxonTtest 基于*差值的绝对值*进行秩次排序,得到统计量T(正差值和负差值中较小的) 比上面的的更适合极端值少的,比较对称的分布
*作用:看两组数据是否有显著的差异*
*H0:正秩和负秩和相等\\两个东西没什么区别*
```{r Wilcoxon-T-test}
# 配对样本 Wilcoxon 符号秩检验适用于两个相关(配对)样本的比较,当差值不满足正态分布时使用
# 假设情景:某减肥机构想评估一种新减肥方法的效果
# 变量含义:体重(公斤)
# 测量前:参与者开始减肥前的体重
# 测量后:参与者经过 8 周方法干预后的体重
# 预期大多数人体重下降,但效果存在个体差异,且差值可能不服从正态分布
two_related_samples <- read_xlsx(here("data", "excel-files", "Wilcoxon_paired_data.xlsx"))
# 进行配对样本 Wilcoxon 符号秩检验
# 检验减肥前后体重是否有显著差异(中位数之差是否为零)
wilcox.test(x = two_related_samples$weight_before,
y = two_related_samples$weight_after,
alternative = "two.sided", # 双侧检验:前后体重不同
paired = TRUE, # 配对样本
exact = FALSE, # 不计算精确 p 值(存在结时避免计算量过大)
correct = FALSE) # 不进行连续性校正
# 注释:
# 若 paired = FALSE,则相当于 Mann-Whitney U 检验(两独立样本)
# exact = FALSE 表示使用正态近似计算 p 值(适用于大样本或存在结的情况)
# correct = FALSE 表示不使用连续性校正
#wilcox.test(x=第一组数据,y=第二组数据,
```
##### 2.1.3. McNemar test
*作用:检验配对\\相关样本的二分类数据差异,检验由二分 / 二元数据(如 “是否为病毒携带者”)量化的两个相关样本。*
通常出现在2\*2列联表形式中。第一行第一列是a,第一行第二列是b,第二行第一列是c,最后一个是d.
计算公式:$p_A=\frac{a+b}{N},p_B=\frac{a+c}{N}$
举例:研究人员试图判断某药物是否有效。
```{r McNemar-test}
# Create the data
drug_effect <-
matrix(c(101,59, 121, 33),
nrow = 2,
dimnames = list("before" = c("present", "absent"),
"after" = c("present", "absent")))
#怎么构建矩阵?matrix(数据向量,nrow=行数,dimnames=list(行名,列名))
#注意r是默认按列填充的,竖着第一,竖着第二,竖着完了轮到第二列
#看第一个矩阵吧,看了就知道 了
# View the data
drug_effect
# Conduct the test
mcnemar.test(drug_effect)
#核心就是mcnemar.test(data)
#correct=,是否做连续性矫正,大样本用F就好
#alternative=,依旧two是默认
```
#### 2.2.Two independent sample两个独立样本检验
##### 2.2.1.Mann-Whitney U test
*作用:独立样本T检验的非参数替代方法,*
*适合有序分类数据,连续但不正态,不方差齐性的数据*
看两组谁分高谁分低
*H0:两组样本来自同一分布,即两组的分布位置相同(中位数相等)*
```{r Mann-Whitney-U}
# 加载所需包
##library(readxl)
# 加载新生成的数据
two_samples_data <- read_xlsx(here("data", "excel-files", "MWU.xlsx"))
# 数据处理(与原代码逻辑100%一致)
temp= two_samples_data$ycss # 提取因变量
group = two_samples_data$zb # 提取分组变量
group1 = temp[group==1] # 筛选分组1数据
group2 = temp[group==2] # 筛选分组2数据
# 执行Mann-Whitney U检验(非配对数据,所以勾选F,使用双尾检验)
wilcox.test(x = group1, y = group2, alternative = "two.sided",
paired = F)
# 生成不含重复值的对比数据
temp_new = c(5.5, 4.6, 4.4, 3.7, 3.401, 3.399, 2.0, 1.9,
1.6, 1.1, 0.802, 0.801, 0.8, 0.799, 0.798,
0, -0.1, -0.2, -1.2, -1.6)
# 按原分组变量筛选(与原逻辑一致)
group1_new = temp_new[group==1];
group2_new = temp_new[group==2];
# 再次执行MWU检验,对比重复值/无重复值的警告差异
wilcox.test(x = group1_new, y = group2_new, alternative = "two.sided",
paired = F)
```
##### 2.2.2 K-S test
*作用:检验两组样本是否来自完全相同的分布(是不是复制粘贴)*
\*对重复值超级敏感\*\*只适合连续性数据\* 数据处理的部分和MU一样
```{r K-S-Test}
# 假设情景:某公司想检验两个不同工厂生产的同型号零件寿命分布是否一致
# 变量含义:
# part_life:零件使用寿命(小时,连续变量)
# factory:工厂编号(1 = 工厂A,2 = 工厂B)
# 预期两个工厂的零件寿命分布可能存在差异(如一个工厂寿命普遍更长或更分散)
# 加载数据
two_samples_data <- read_xlsx(here("data", "excel-files", "Onesampleks.xlsx"))
# 数据处理
temp <- two_samples_data$part_life # 零件寿命
group <- two_samples_data$factory # 工厂分组
group1 <- temp[group == 1] # 工厂A的寿命数据
group2 <- temp[group == 2] # 工厂B的寿命数据
# 进行两样本 Kolmogorov-Smirnov 检验
# 原假设:两个工厂的零件寿命分布相同
# 备择假设:分布不同(双侧检验)
ks.test(group1, group2, alternative = "two.sided")
#ks.test(数据集1,数据2,alternative=)
```
##### 2.2.3 Moses Extreme Reaction test
一种非参数检验方法,用于检验两个独立样本的总体在**极端值表现上**是否存在显著差异。
*作用:主要用于检验两个独立样本来自的总体在极端值方面是否存在显著差异.*
*H0:两独立样本来自的总体分布无显著差异,即两组的极端值无明显区别*
也就是 “两总体分布无显著差异(控制样本与实验样本的极值无差异)”;若实验样本相对控制样本出现显著的极端反应(极值差异显著),则拒绝原假设,认为两总体分布存在差异。
核心步骤
1. 混合排序:将两组数据合并并升序排序;
2. 计算跨度:基于控制样本的最小/最大秩次,计算跨度 S=Qmax−Qmin+1;
3. 也可以选择截头跨度:剔除控制样本部分观测值,消除极端值对结果的影响后再计算跨度。
决策规则:根据跨度/截头跨度计算 P 值,若 P≤α(显著性水平),则拒绝原假设,判定两总体分布存在显著差异;反之则接受原假设。*\
*数据处理部分和MWU一模一样,空值(Null)或整数表示要从两个极端剔除的百分比.
```{r Moses-Extreme-Reaction-test}
#library(DescTools)
# Load the data
two_samples_data <- read_xlsx(here("data","excel-files","Mosesextremetest.xlsx"))
# data processing
temp = two_samples_data$ycss;#因变量
group = two_samples_data$zb;#分组变量
group1 = temp[group==1];#第一组数据
group2 = temp[group==2];#第二组数据
# Conduct the test
# Null or an integer number indicates the percentage to be dropped from the two extremes
# NULL=不剔除极端值;输入数字=剔除指定比例的极端值
MosesTest(group1, group2, NULL)
#MosesTest(数据1,数据2,NULL)
```
##### 2.2.4Wald-Wolfowitz Runs test
Wald-Wolfowitz Runs test(沃尔德-沃尔沃思游程检验)是一种非参数检验方法,用于检验两个独立样本是否来自同一个总体或具有相同的分布。以下为你详细介绍:
1. 基本概念:
- 游程(Run):是指在一个序列中,相同元素的连续出现。例如,对于序列“正正反反反”,这里有4个游程,分别是“正正”“反”“正”“反反”。
- 原假设:两个独立样本来自同一个总体,即它们的分布是相同的;备择假设:两个样本来自不同的总体,即它们的分布不同。
2. 检验步骤:
- 合并与排序:将两个独立样本的数据合并成一个序列,并按照从小到大(或从大到小)的顺序进行排列。
- 确定游程数:给合并后的序列中的每个数据标记其所属的样本来源(例如,样本A或样本B),然后统计序列中的游程数量。
- 计算统计量:根据样本大小n₁(样本1的大小)和n₂(样本2的大小)以及游程数R,计算检验统计量。\
在大样本情况下(一般n₁和n₂都大于20时),游程数R近似服从正态分布,\
$$
均值:\mu_R = \frac{2n_1n_2}{n_1 + n_2} + 1
$$
$$
标准差:\sigma_R = \sqrt{\frac{2n_1n_2(2n_1n_2 - n_1 - n_2)}{(n_1 + n_2)^2(n_1 + n_2 - 1)}}\
$$
$$
Z统计量: Z=\frac{R-\mu_R}{\sigma_R}
$$
- 决策判断:根据计算得到的统计量Z(或在小样本情况下根据游程数R的临界值)与相应的显著性水平(如α = 0.05)下的临界值进行比较。如果\|Z\|大于临界值(或游程数R小于或大于相应的临界值),则拒绝原假设,认为两个样本来自不同的总体;否则,不拒绝原假设,认为两个样本可能来自同一个总体。
```{r Wald-Wolfowitz-Runs-test}
# Load the packages
#library(haven)
#library(DescTools)
# 读取数据(按照要求修改为Excel读取路径)
two_samples_data <- read_xlsx(here("data","excel-files","WaldWRunstest.xlsx"))
# 数据处理
temp = two_samples_data$ycss; # 因变量
group = two_samples_data$zb; # 分组变量
group1 = temp[group==1]; # 分组1的因变量数据
group2 = temp[group==2]; # 分组2的因变量数据
# 若不指定y参数,则用于检验二分类分布的随机性(上面的)
RunsTest(x = group1, y = group2, alternative="two.sided",exact=TRUE)
#有时候输出结果会是一串警告
#会告诉你数据有很多tie值
# tie指的是数据集合中的重复值,其实这个tie值也是让人很没招的东西
```
### *③Non-parametric Test III K个样本非参数检验*
非参数检验III K个样本(相关\\独立)的非参数检验和非参数相关分析,是参数检验(ANOVA,皮尔逊相关)的替代方案,适用于不满足正态性,存在异常值,数据为等级\\二分类的场景.
#### 3.1 K relateed SamplesK个相关样本检验
适用于同一对象接受K次处理,同一评分员评K个对象等重复测量\\随机区组设计,
替代单因素重复测量ANOVA,核心检验K个相关组的分布位置\\一致性差异\
##### 3.1.1.Friedman test & Kendall's W
*作用:随机区组设计的核心非参数检验,替代单因素重复测量ANOVA,检验K个相关样本的概率分布位置是否存在显著差异.*
适用范围:数据类型为计量(区间\\比率)或有序等级数据;
K个相关样本(随机区组),处理在区组内随机分配;
前提:存在异常值\\不满足正态性(参数ANOVA前提), 块数b或处理数k至少一个\>5(大样本卡方近似
*H0:K个处理(treatment)的**概率**分布完全相同(但是你不知道实际怎么分布);\
*(n或者b=区组数\\块数,k=受试者数量,也写作$\chi_r^2$)
检验统计量:
$$
检验统计量:
F_r = \left\{ \frac{12}{bk(k+1)} \right\} \sum_{i=1}^{k} R_i^2 - 3b(k+1)
$$b = 区组数
k = 处理数
Ri = 第 i 个处理的秩和(每个数据的秩是在其所在区组内按大小计算的)
$$
拒绝域:F_r>\chi_{\alpha}^2,df=k-1
$$判定:(卡方临界值,df=k-1)→拒绝H0;\
小样本查专用临界值表.卡方通常找右边的尾巴,所以通常是大于临界值是拒绝H0
缺陷:仅检验分布位置,无法检验分布形状\\离散度;小样本需查专用临界值表;结值过多时拉完了
```{r Friedman-test}
# Friedman test n个配对样本检验 和Kw本质上是一个东西,但这个更多是看被评价者之间有无区别,KW是看评委的给分一致性
# 读取Excel数据
k_related_samples <- read_xlsx(here("data","excel-files","Friedmantest.xlsx"))
# 将数据框转换为矩阵格式(friedman.test函数要求矩阵输入)
k_related_samples <- as.matrix(k_related_samples)
# 检验目的:判断3款笔记本电脑的满意度评分是否存在显著差异
# 选择列2:4(对应3款产品的评分数据,剔除ID列)
friedman.test(k_related_samples[, 2:4])
# 计算Kendall和谐系数
# 目的:衡量测评者评分的一致性程度(值越接近1,一致性越高)
# t() 转置数据:适配irr::kendall函数的输入格式要求
irr::kendall(t(k_related_samples[, 2:4]))
```
##### 3.1.2.Cochran's Q
作用:McNemar检验的K样本延伸,检验K个相关样本的二分类数据分布是否存在差异,核心分析多个相关二分类组的概率差异
适用范围:数据类型:*只能是*严格二分类数据(0\\1,如通过\\失败,及格\\不及格);
自变量连续,因变量二分类 同一对象接受K个处理的二分类结果,K个相关样本.
*H0:K个处理的二分类结果概率分布完全相同;*
```{r Cochrans-Q-test}
# Cochran's Q test 自变量连续 因变量二分类
# dichotomous data; eg: success\failing
# Load the package used to conduct the test
#library(rstatix)
# create the data
mydata = data.frame(
outcome = c(0,1,1,0,1,1,1,1,1,1,0,1,0,0,0,1,1,1,1,0,1,1,1,1,0,0,1,0,0,1),
treatment = gl(3,1,30,labels=LETTERS[1:3]),
participant = gl(10,3,labels=letters[1:10])#3个元素,一个元素重复1次,总共有30个
)
#gl(水平数,每个水平重复数,总数据量,labels=分组名)
head(mydata)
# conduct the test
cochran_qtest(mydata, outcome ~ treatment|participant)
#cochran_qtest(数据框,二分类结果~处理组|ID)
#缺陷:仅能处理二分类数据
#小样本时卡方近似效果差,拉完了.无统一的结值处理标准,结果易受影响.
```
#### 3.2 k个独立分组检验
(如不同职业,不同工艺组),替代单因素独立样本ANOVA,核心检验K个独立组的分布位置\\中位数\\趋势差异
##### 3.2.1.Kruskal-Wallis test
*作用:非参数版单因素独立样本ANOVA,是Mann-WhitneyU检验的K样本延伸,检验K个独立样本的概率分布位置是否存在显著差异.*
适用范围 数据类型:计量(区间\\比率)或有序等级数据;
设计:K个独立随机样本,每个样本量≥5(大样本卡方近似);
前提:不满足正态性\\方差齐性(参数ANOVA前提).k个样本是随机且独立抽取的,每组数据至少有5个。
*H0:K个总体的分布完全相同;\
Ha:至少有两个总体的分布在位置(中位数)上存在差异。*
公式:$H = \frac{12}{n(n+1)}\sum_{i=1}^{k}\frac{R_i^2}{n_i}-3(n+1)$
n:所有样本的总观测数(n=n1+n2+⋯+nk)
n_i:第i个样本的观测数(第i组的样本量)
R_i:第i个样本的秩和(先将所有样本数据合并排序,计算每个观测值的秩,再按组汇总得到各组的秩和)
若$H>\chi_{a}^2(df=k-1)$ 则拒绝H0,认为至少两组总体的分布存在显著差异。
类似MWU,如果组别数应该相似差别不大,秩次应该混合
判定:H服从卡方分布(df=k-1),
```{r Kruskal-Wallis-test}
#举个例子:研究 ** 三种饲料类型(分组变量ff)对小鼠运动耐力得分(因变量ydp1)** 的影响,共 3 组独立样本:
#ff=1:常规
#ff=2:高蛋白
#ff=3:低蛋白
#因变量ydp1为小鼠运动耐力评分(连续数值,不满足正态分布),因此用 Kruskal-Wallis 检验。
# library(readxl)
k_indpt_samples <- read_xlsx(here("data", "excel-files", "KruskalWallistest.xlsx"))
# 将分组变量转换为因子型:检验要求分组变量必须是因子/字符型
k_indpt_samples$ff <- as.factor(k_indpt_samples$ff)
# 执行Kruskal-Wallis
kruskal.test(ydp1 ~ ff, data = k_indpt_samples)
#k_indpt_samples$分组变量=as.factor(k_indpt_samples$分组变量)
#kruskal.test(因变量~分组变量,data=k_indpt_samples)
```
##### 3.2.2.Median test
```{r}
# Median test 其实没有什么用,不再详细展开
# Load the package used to read .sav data
#library(haven)
#k_indpt_samples = read_sav(here("data", "sav_files", "Data12-07.sav"))
#k_indpt_samples$ff = as.factor(k_indpt_samples$ff)
# Load the package used to conduct the test
#library(agricolae)
# conduct the test
#Median.test(k_indpt_samples$ydp1,k_indpt_samples$ff)
```
##### 3.2.3.Jonckheere-Terpstra test
*作用:Mann-WhitneyU检验的K样本延伸,专门检验有序分组的K个独立样本的分布位置是否存在单调趋势(如随剂量升高,中位数递增),比K-W检验更适用于有序分组.*
适用范围 数据类型:计量\\等级数据;
它是有一个先验单调假设的,如果这个假设是错的,JT检验就不好使
设计:K个独立样本,分组变量为有序分类(如年龄组:青年\\中年\\老年;剂量组:低\\中\\高);
优势:检测趋势性差异的效能远高于K-W检验.
*H0:K个有序总体的分布位置无单调趋势;\
Ha:K个有序总体的分布位置存在单调趋势(递增\\递减)*
```{r JonckheereTerpstraTest}
# Jonckheere-Terpstra检验 说明:组别存在明确顺序且有趋势假设时使用,仅检验有无差异用KW检验
# 分组变量必须是有序因子或数值型
#举例:研究三种剂量的褪黑素(有序分组:低剂量→中剂量→高剂量)
#对小鼠睡眠时长(分钟)的影响,假设睡眠时长随褪黑素剂量升高逐步递增(有序趋势)
# 读取Excel数据
k_indpt_samples <- read_xlsx(here("data", "excel-files", "JonckheereTerpstraTest.xlsx"))
# 将分组变量转换为有序因子:JT检验的强制要求as.factor,否则会报错
k_indpt_samples$ff <- as.ordered(k_indpt_samples$ff)
# 执行Jonckheere-Terpstra检验(标准)
JonckheereTerpstraTest(k_indpt_samples$ydp1, k_indpt_samples$ff)
#JonckheereTerpstraTest(x=因变量,g=分类变量,alternative=,nperm=)
# 执行JT检验:nperm=5000表示用5000次随机置换计算经验p值,小样本数据推荐使用
JonckheereTerpstraTest(k_indpt_samples$ydp1, k_indpt_samples$ff, nperm=5000)
# x=因变量,必须是数值型numeric,每个样本对应一个数值
# g=分组变量,必须是有序因子factor
# nperm=随机置换分组的次数,小样本时用置换法提高p值准确性
#但是nprem下每次的结果可能会有不同,这是在正常的
```
## 二.Nonparametric correlation tests非参数相关性
::: rmdnote
**为什么用非参数相关性?**
非参数相关性(如Spearman秩相关)用于变量间不满足线性、正态或等距时,基于秩次度量单调关联,更稳健。
非参数检验则用于比较组间差异(如Mann-Whitney)。
区别:前者评估两个变量的相关强度与方向;后者检验分组变量对结果的影响是否存在显著差异。两者均不依赖分布假设。
:::
### 4.1 Kendall's tau
作用:衡量两个有序变量之间的秩相关强度和方向
*适用于:变量是排名\\等级(ranking)更适合小样本*
*H0:两个有序变量没有秩相关(顺序完全随机\\A情况排名和B情况排名没有关联)*
```{r kendalls-tau}
# 模拟情景:研究 50 名中学生的课堂专注度排名与期末考试成绩排名的相关性变量含义:
#student_id:学生唯一编号(标识变量)
#focus_rank:课堂专注度排名(有序数值,1 = 最专注,50 = 专注度最低)
#score_rank:期末考试成绩排名(有序数值,1 = 成绩最高,50 = 成绩最低)
data2 <- read_xlsx(here("data", "excel-files", "Kendallstau.xlsx"))
# 第一个变量:focus_rank = 课堂专注度排名(有序变量)
# 第二个变量:score_rank = 期末考试成绩排名(有序变量)
# alternative = "two.sided":双侧检验,检验是否存在相关性(正相关/负相关均可)
# method = "kendall":指定使用Kendall's tau相关系数
cor.test(data2$focus_rank,
data2$score_rank,
alternative = "two.sided",
method = "kendall")
#cor.test(第一个有序变量,第二个有序变量,alternative=,method=) #two.sided检测是不是相关,less是负相关,greater是正相关
```
### 4.2 Kendall's W
*作用:衡量评分者对同一组对象评分的一致性程度\
H0:评分者之间完全不一致(排名随机,无共识)*\
只处理秩次\\排名数据 W接近1→一致性很强;\
接近0→一致性很弱 χ2\>χdf,α2(或p\<α)→拒绝H0,认为评分者间存在显著一致性.\
(其实很多涉及$\chi$ 值的都是算出来的$\chi$ 大于临界就拒绝零假设
```{r kendalls-w}
#模拟情景:4 位老吃家,对 10 款蛋糕的口感进行 1-10 分打分,检验老吃家们的评分结果是否具有一致性
#judge:评委编号(4 位老吃家,对应数据的行)
#cake1至cake10:10 款蛋糕的口感评分(1-10 分,对应数据的列)
# Kendall's W和谐系数:检验多个评价者对多个对象的评分一致性
# 读取Excel数据
data3 <- read_xlsx(here("data", "excel-files", "KendallsW.xlsx"))
# 查看数据前几行,确认数据格式正确
head(data3)
# 执行Kendall's W检验
# 强制使用irr包的kendall函数,避免环境中重名函数导致错误
# 数据处理逻辑:1:4 代表4行是4位评委的打分数据,2:11 代表2-11列是10款蛋糕的评分
# t() 转置数据,是irr包kendall函数的格式要求
irr::kendall(t(data3[1:4, 2:11]))
# 操作解释:
# 行1:4:选取所有评委的打分行,对应评价者
# 列2:11:排除评委名称列,仅保留蛋糕评分列,对应评价对象
# 转置数据:函数要求行为评价对象、列为评价者,因此必须用t()转换格式
```
### 4.3 Spearman Correlation
作用:替代皮尔逊相关,衡量两个变量间的**单调相关程度**(非严格线性),是最常用的非参数相关指标.
适用范围
数据类型:有序等级数据,或计量数据但不满足正态性;
变量关系:变量间存在单调关系(递增\\递减,非严格线性);
*H0:两个变量间无单调相关(ρ=0);*
*H1:两个变量间存在显著单调相关(ρ≠0\\ρ\>0\\ρ\<0,单侧\\双侧)*
计算斯皮尔曼相关系数需要:
每个个体都观测两个变量。\
对每个变量的观测值分别进行等级排序(X 和 Y 各自独立排序)。\
变量排序后,通过以下方式计算斯皮尔曼相关:\
a. 对排序后的数据使用皮尔逊公式;\
b. 或使用斯皮尔曼专用公式(适用于几乎没有或仅有少量相同等级的情况)。
```{r Spearman-test}
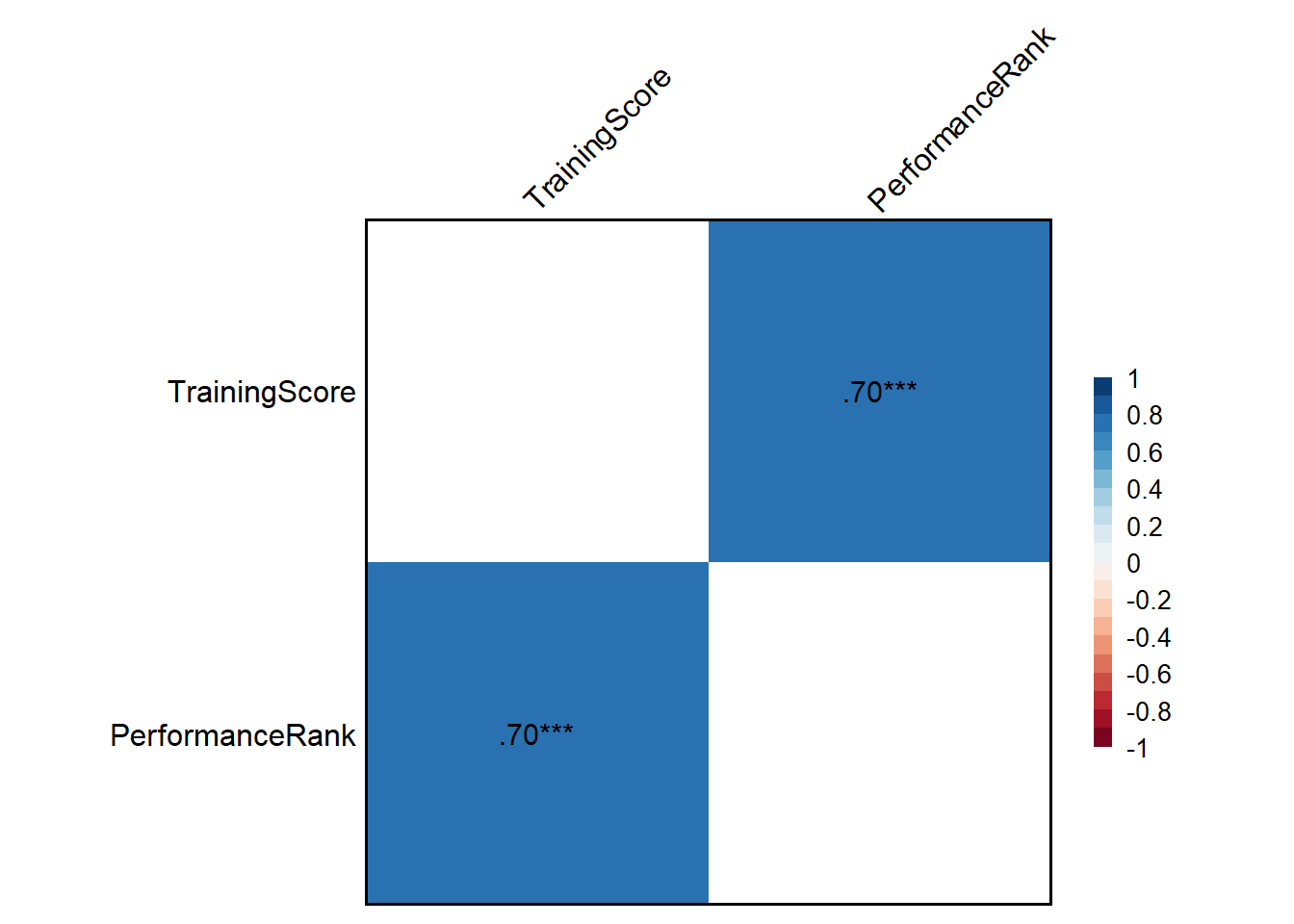
# 假设情景:某公司人力资源部门想评估员工培训评分与绩效评级之间的单调关系。
# 培训评分(TrainingScore)为员工在培训结束后的测试得分(整数,范围1-10,1分最低,10分最高),属于有序变量。
# 绩效评级(PerformanceRank)为年度绩效评定等级(转换为整数1-5,1为最差,5为最佳),也属于有序变量。
# 预期假设:培训评分越高,绩效评级也越高(正相关),但存在个体差异和其他影响因素(如工作经验、团队氛围等),因此数据不是完美相关,也不是纯噪音。
data_spearman <- read_xlsx(here("data", "excel-files", "Spearmantest.xlsx"))
# 提取两个变量
x <- data_spearman$TrainingScore # 培训评分(有序变量)
y <- data_spearman$PerformanceRank # 绩效评级(有序变量)
# 使用bruceR包中的Corr函数进行斯皮尔曼相关分析(输出更豪坎)
# 该函数自动处理缺失值并显示显著性
Corr(data_spearman[,1:2], method = "spearman")
# 使用基础库的cor.test进行斯皮尔曼检验,同时输出详细统计量(包括p值和置信区间)
# 由于变量是有序的或不满足正态分布,应该使用斯皮尔曼方法评估单调相关性
cor.test(x, y, method = "spearman")
# 对比:皮尔逊方法适合正态且线性关系,此处仅作为演示
# 因为数据并非连续正态,且存在等级关系,皮尔逊结果可能不准确
# cor.test(x, y, method = "pearson")
#data=read_excel(“iq_test.xlsx”)
#x=data$x,y=data$y
#cor.test(x,y,method="spearman")
#pearson:适合正态分布+线性,重点是线性
#spearman适合非正态\等级\非线性,重点是单调相关程
```
### 4.4Point biserial correlation点二列相关
作用:衡量一个**真正二分类变量**与一个计量\\等距变量间的相关程度,是皮尔逊相关的特殊形式,也可作为独立样本t检验的效应量指标.
适用范围:变量类型:一个为真正二分类变量(如性别,是否患病,非人为二分),另一个为计量\\等距变量;.
$H_0$ :二分类变量与计量变量间无相关($r_{pb}=0$ );
$H_1$ :两者间存在显著相关($r_{pb}\neq0$).
当数据包含一个二分变量和一个数值变量时,二分变量可用于将个体分为两组。 然后,可以计算每组中数值变量的样本均值:
$$
r_{pb} = \sqrt{\frac{t^2}{t^2 + df}}
$$
cor.test(二分类变量,连续变量)
#连续变量需要满足正态性
```{r point-biserial-correlation}
# 点二列相关适用于一个二分变量和一个数值变量
# 假设情景:比较两种教学方法对学生考试成绩的影响
# 二分变量:教学方法(0 = 传统教学,1 = 创新教学)
# 数值变量:考试成绩(百分制,范围 0-100)
# 预期创新教学的学生平均成绩更高,但存在个体差异和随机误差
# 读取生成的数据
data_pb <- read_xlsx(here("data", "excel-files", "Point-bioserial-correlation.xlsx"))
# 提取两个变量
x <- data_pb$condition # 二分变量:教学方法(0=传统,1=创新)
y <- data_pb$grade # 数值变量:考试成绩
# 进行点二列相关检验(cor.test 会自动识别二分变量与数值变量,得到点二列相关系数)
# 由于变量为二分与连续,点二列相关等价于皮尔逊相关,因此直接用 cor.test 即可
cor.test(x, y)
```
### 4.5 Phi Coefficient
专门针对2\*2列联表的相关系数。
适合范围:两个变量均为自然二分(二分类且无序)的场合,例如医学中治疗有效/无效与存活/死亡,或市场研究中购买/未购买与男性/女性。
Phi系数常与卡方检验联用,用于量化显著性背后的实际关联大小。
```{r Phi-coefficient}
# Phi Coefficient 一列是二分类,另一列是连续
phi_data <- read_xlsx(here("data", "excel-files", "Phi-coefficient.xlsx"))
# 提取两个二分变量
x <- phi_data$teaching # 教学方式(1=创新,0=传统)
y <- phi_data$attitude # 学习态度(1=积极,0=消极)
# 方法一:使用 psych 包中的 phi() 函数,需要从列联表计算
# 生成 2x2 列联表
contingency_table <- table(x, y)
# 计算 φ 系数
phi_correlation <- phi(contingency_table)
phi_correlation
# 方法二:使用 cor.test 直接对两个二分变量进行皮尔逊相关,结果等价于 φ 系数
cor.test(x, y)
```